Distributionally Robust Sequential Recommendation
1.Abstract
Modeling user sequential behaviors have been proven effective in promoting the recommendation performance. While previous work has achieved remarkable successes, they mostly assume that the training and testing distributions are consistent, which may contradict with the dynamic nature of the user preference, and lead to lowered recommendation performance. To alleviate this problem, in this paper, we propose a robust sequential recommender framework to overcome the distribution shift. In specific, we first simulate different distributions by reweighting the training samples. Then, the maximum loss induced by the various sample distributions is minimized to optimize the 'worst-case' model for improving the robustness. Considering that there can be too many sample weights, which may introduce too much flexibility and be hard to converge, we cluster the training samples based on both hard and soft strategies, and assign each cluster with a unified weight. At last, we analyze our framework by presenting the generalization error bound of the above minimax objective, which is expected to better understand our framework from the theory perspective. We conduct extensive experiments based on three real-world datasets to demonstrate the effectiveness of our proposed framework. Empirical results suggest that our framework can on average improve the performance by about 2.27% and 3.51% on Recall and NDCG respectively.
2.Motivating Examples
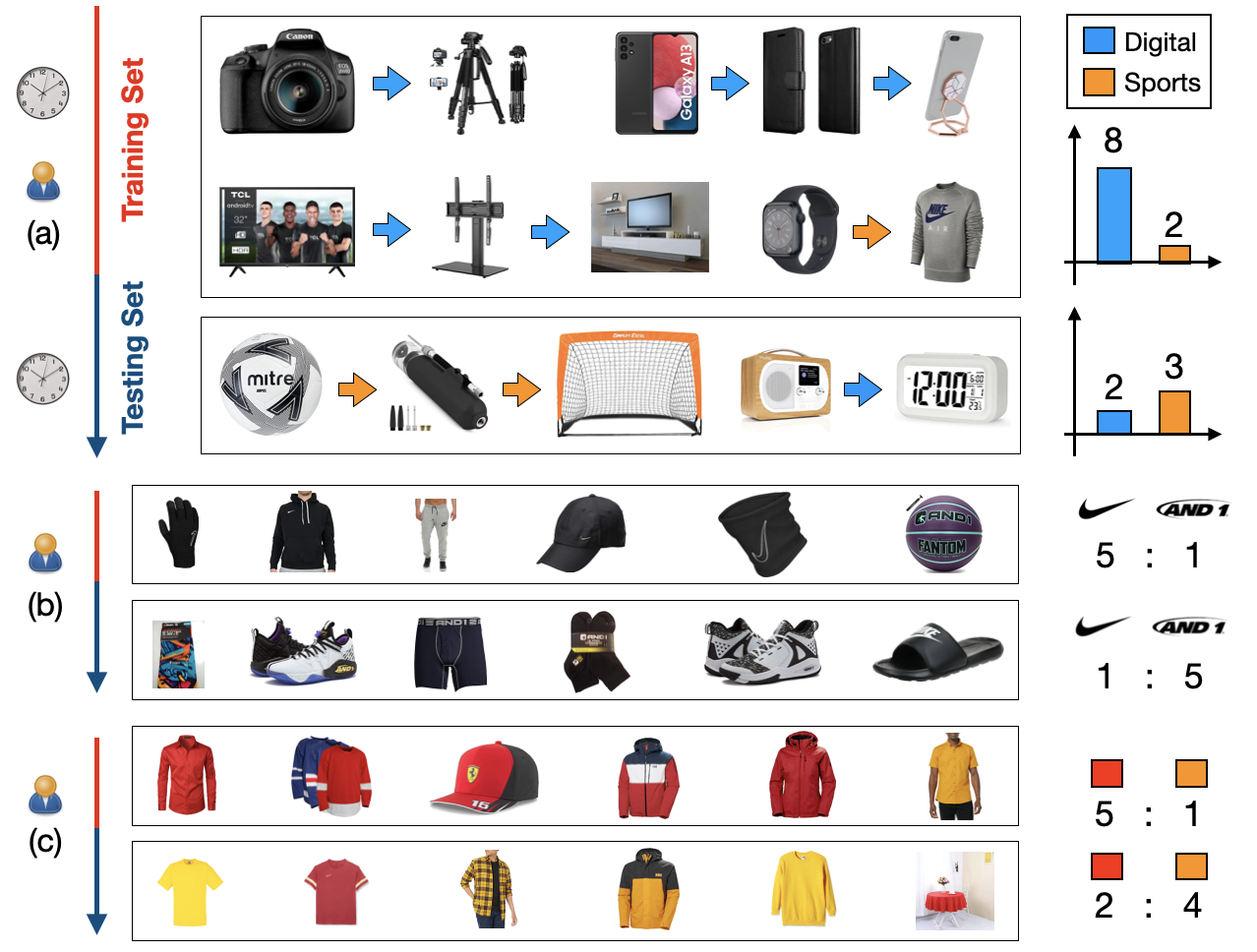
Figure 1: (a) Example of the user preference shift from digital products to sports items.
(b) and (c) Examples of the user preference changes on the item brands and colors
3.Contributions
In a summary, the main contributions of this paper are presented as follows:
We propose a robust framework for sequential recommendation, which to the best of our knowledge, is the first time in the recommendation domain.
To achieve the above idea, we firstly design a basic model by tuning the sample weights. Then, we improve the basic model by clustering the training samples based on both soft and hard strategies.
We provide theoretical analysis on the designed framework based on the probably approximately correct (PAC) learning theory.
We conduct extensive experiments to evaluate our framework, and for promoting this direction, we have released our project at https://anonymousrsr.github.io/RSR/ .
4.Code and Datasets
4.1 Code files link:One Drive
| datasets | Dataset folder |
|---|---|
| models | Basemodel and our framework program |
| utility | Utils program |
| run_RSR.py | Quick start program |
| main.py | Training program |
4.1 Datasets overview link:One Drive
| Dataset | # User | # Item | # Interactions | Ave.Sl | Sparsity |
|---|---|---|---|---|---|
| Sports | 35,598 | 18,357 | 286,207 | 8.02 | 99.95% |
| Toys | 19,412 | 11,924 | 156,072 | 8.04 | 99.93% |
| Yelp | 30,431 | 20,033 | 282,399 | 9.28 | 99.95% |
5.Usage
- Download the code.
- Download the dataset, and put it into the datasets folder.
- run run_RSR.py file.
- For example use soft-clustering framework and GRU4Rec as the basemodel on Sports with 10% noisy ratio.
xxxxxxxxxxpython run_RSR.py -d sports -base GRU4REC -t l_w -noisy 10
6.Detailed parameter search ranges
We tune hyper-parameters according to the following table.
| Hyper-parameter | Explanation | Range |
|---|---|---|
| lr_base | Learning rate of basemodel | {0.1, 0.01, 0.001, 0.0001, 0.00001} |
| lr_w | Learning rate of weight vector | {0.1, 0.01, 0.001, 0.0001, 0.00001} |
| lr_f | Learning rate of cluster component | {0.1, 0.01, 0.001, 0.0001, 0.00001} |
| BatchSize | Batch Size | {32, 64, 128, 256, 512, 1024} |
| K | Class number | {4, 8, 16, 32, 64, 128} |
| temperature | Temperature coefficient in softmax | {0.01, 0.1, 0.2, 0.4, 0.6, 0.8, 1, 2, 100} |
| lambda | Scale weight of Clustering Loss | {0.0001, 0.0005,0.001,0.005, 0.01, 0.05} |
7.Runtime Environment
System:Linux 20.04.2-Ubuntu
CPU: 96 Intel(R) Xeon(R) Gold 5318Y CPU @ 2.10GHz
CPU-Memory:256G
GPU:NVIDIA Corporation NVIDIA A40
Pytorch: 1.11.0
CUDA:11.6